公众号文章批量采集完全指南:5种方法 + API逆向 + 实战脚本
中文互联网上最好的商业写作,有一半锁在公众号里。
你能看,但你搬不走。你能收藏,但你检索不了。你能截图,但你没法喂给AI。
这道围墙的缝隙在哪?我找到了5条。
这周日实测:一个公众号,533篇文章,横跨9年——84秒拿到全部URL列表,18分钟下载为Markdown,零失败。从淘宝2.99元的代采集,到自己逆向API写脚本,5种方案按难度排列,总有一条适合你。
先说结论
别急着往下翻,先看这张表,找到适合你的方案直接跳过去看:
你的情况 推荐方案 成本 耗时 什么都不想干 淘宝代采集 3元/号 等1天 会点浏览器操作 开源工具 changfengbox 0 30分钟 要对接自动化工作流 wxrank.com API 2分/篇 按需 想走官方合规渠道 微信读书 0 2小时 想要完全自主可控 接口逆向 + 脚本 0 1小时搭建,之后无限复用
下面逐个拆解。
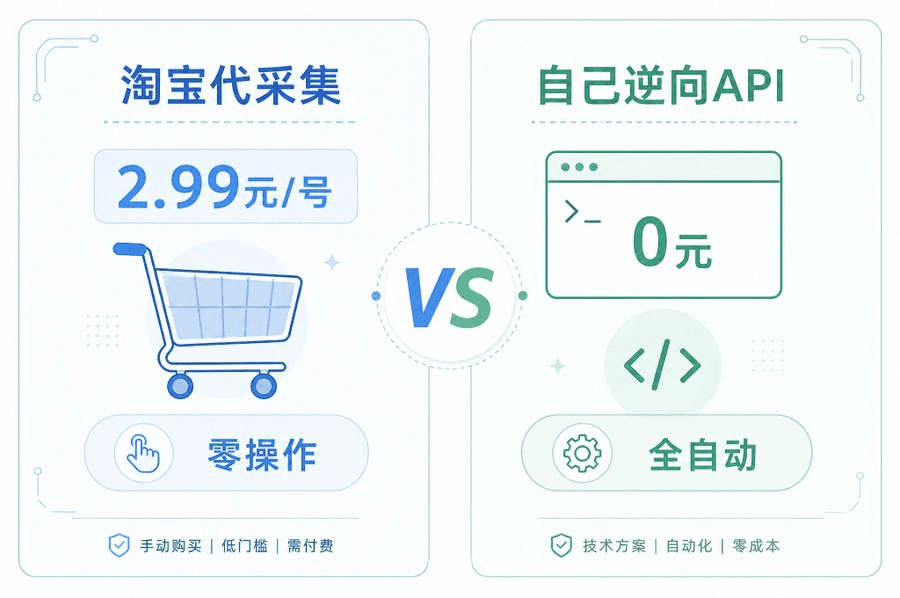
01. 淘宝代采集:2.99元,什么都不用干
这是我见过性价比最离谱的方案。
打开淘宝,搜「公众号文章采集」,一堆商家,行业均价 2.99元一个号。你把公众号名字发过去,约定好格式(PDF、Word、Excel都行),商家交付的结果里包含:
- 每篇文章的完整内容
- 原始URL链接
- 发布时间
- 封面图
一万篇文章的总费用也就几十块钱。
适合谁? 不想折腾技术,只想拿到结果的人。
缺点? 需要等商家处理,通常几个小时。格式可能不是你想要的Markdown。但拿到URL列表后,可以用后面的方法自己转格式。
02. 开源工具:changfengbox 一键下载
GitHub上有个15000 Star的项目叫wechatDownload,同时提供了一个免费的网页版:
https://changfengbox.top/wechat
使用方法
Step 1: 粘贴目标公众号的任意一篇文章链接 Step 2: 点击「获取公众号id」,工具自动生成一个密钥链接 Step 3: 把这个链接复制到微信里打开(发给「文件传输助手」再点开就行) Step 4: 工具自动获取访问密钥,然后加载出全部文章列表 Step 5: 设置参数后一键批量下载:
- 时间范围:全部
- 开始下载页数:-1(代表全部)
- 格式:勾选MD(Markdown)
- 点击「批量下载」
注意事项:
- 桌面客户端仅支持Windows
- 网页版跨平台,但功能相对精简
- 如果获取密钥失败,关掉梯子再试
- 文章太多(超过50页)不要一次抓完,分批来,避免接口被封
这个方案的核心优势是免费 + 可视化操作,不需要写一行代码。
03. 微信读书:合规的官方渠道
如果你对合规性有要求,这条路最干净。
Step 1: 手机打开微信读书APP → 搜索目标公众号 → 添加到书架 注意:添加的是整个公众号账号,不是单篇文章。添加后,公众号的所有历史文章都会出现在你的书架上。 Step 2: PC端打开微信读书网页版 → 登录 → 获取cookie Step 3: 通过接口批量拉取全量文章 可以用Coze搭一个工作流,自动把所有文章存进飞书多维表格。 优点: 走官方渠道,合规性最强。 缺点: 流程繁琐,需要一定技术基础来自动化。
04. 第三方数据API:按篇计费,适合自动化
如果你需要把采集接入自动化工作流(比如n8n、Coze、Make),可以用第三方数据平台。
- 微信扫码注册,不需要手机号
- 最低充值10元
- 单篇文章获取内容+数据仅需 2分钱
- 一万篇总费用约200元
对比另一个常见平台「极致了」:搜一搜单次调用0.5元只返回15条结果,万篇级采集成本极高,不推荐。
05. 接口逆向 + 自己写脚本:终极方案
这是我实际跑通的方案,也是本文的重头戏。
整个链路分两步:拿到文章URL列表 + 批量下载为Markdown。
第一步:拿到URL列表
每个公众号都有一个唯一标识叫__biz,从任意一篇文章的链接里就能提取:
https://mp.weixin.qq.com/s?__biz=MzU4NDY2MDMzMA==&… ↑ 这就是 __biz
有了__biz,还需要两个认证参数:key和pass_ticket。
这两个参数只存在于微信客户端和微信服务器之间的通信中。怎么拿?用中间人代理。
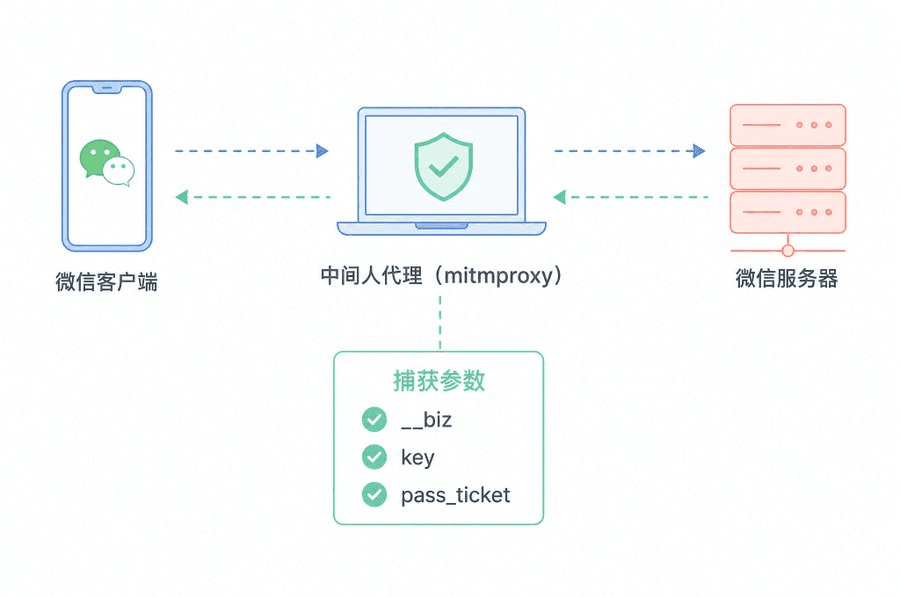
我的做法:
- Mac上启动mitmproxy(一个开源的HTTPS代理工具)
- 写一个10行的Python脚本,让它监听所有发往mp.weixin.qq.com的请求
- 把Mac的系统代理指向localhost:8080
- 在微信里随便打开目标公众号的一篇文章
点击文章的瞬间,mitmproxy就会拦截到请求,自动提取出__biz、key、pass_ticket三个参数。
拿到参数后,关掉代理,开始调接口:
resp = requests.get(
“https://mp.weixin.qq.com/mp/profile_ext”,
params={
“action”: “getmsg”,
“__biz”: “”,
“key”: “捕获到的key”,
“pass_ticket”: “捕获到的pass_ticket”,
“offset”: 0,
“count”: 10
}
)
接口每次返回10篇文章的标题、URL、发布时间。返回值里有一个can_msg_continue字段,值为1就代表后面还有,继续翻页。
533篇文章,翻了44页,每页等2秒,84秒拉完。
第二步:批量下载为Markdown
URL列表有了,怎么把文章内容下载下来?

我逆向了一个网页版服务的API。整个过程只花了3分钟:
- 用Playwright抓取了网页版下载文章时的网络请求
- 发现API端点:POST https://domainname/api/download/wechat
- 请求头里有两个签名字段:x-timestamp和x-sign
- 下载前端JS,一行grep就找到签名算法
签名算法极其简单:
import hashlib, time
timestamp = int(time.time())
sign = hashlib.md5(f”{timestamp}changfengbox.top“.encode()).hexdigest()
对,就是把时间戳和域名拼起来做MD5。密钥是硬编码在前端JS里的。
有了签名,批量下载就是一个for循环的事:
for url in article_urls:
# 1. 调API,传入文章URL
resp = requests.post(API_URL,
headers={“x-timestamp”: ts, “x-sign”: sign},
json={“url”: url, “config”: {“MD”: True}})# 2. 从返回值拿到Markdown文件的下载链接 md_url = resp.json()[“urls”][0] # 3. 下载并保存 content = requests.get(md_url).content save_to_file(content) time.sleep(2) # 间隔2秒,别太暴力
533篇,零失败,18分钟跑完。
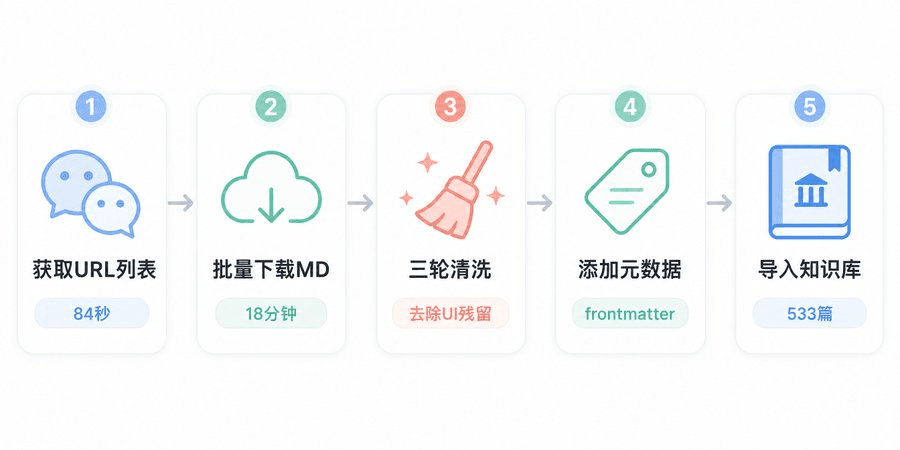
采集后的清洗:别忘了这一步
下载下来的Markdown不能直接用,微信会在文章里塞一堆UI残留:
- 底部的「微信扫一扫关注该公众号」
- 分享/点赞/收藏按钮的文字残留
- 「在小说阅读器读本章」的阅读器入口
- 各种空白行和格式碎片
我写了一个Python脚本做三轮清洗:
第一轮: 从× 分析标记往下全部删除(微信UI块的起始位置) 第二轮: 逐行清理底部残留(「预览时标签不可点」「使用小程序」等) 第三轮: 格式优化(压缩连续空行、修复转义字符、清理空bold标记)
三轮下来,533篇文章从微信风格变成了干净的标准Markdown,可以直接导入Obsidian、Notion、或者任何知识库工具。

几个防踩坑的建议
1. 做好断点续传
批量下载500+篇文章,中途网络断了很常见。每下载10篇就把进度保存一次,重跑时自动跳过已完成的。
2. 控制请求频率
别一秒一篇地暴力请求。每篇间隔2-3秒是安全线。太快了接口会返回错误,严重的话会被封。
3. 认证参数会过期
通过mitmproxy捕获的key和pass_ticket有时效性。如果中途失效了,重新在微信里打开一篇文章就能刷新。
4. 备用下载方案
如果changfengbox API挂了或者限流了,还有两个备选:
- jina.ai Reader: curl https://r.jina.ai/文章URL,免费,大部分公众号文章能抓到
- Playwright浏览器自动化: 真实浏览器渲染,能绕过微信的验证墙,是终极兜底方案
完整工具链一览
环节 工具 作用 拿URL列表 mitmproxy + 微信接口 分页拉取全部文章链接 下载文章 changfengbox API(已逆向) URL → Markdown 签名鉴权 MD5(timestamp + “changfengbox.top“) API调用必需 内容清洗 Python正则(3轮) 去除微信UI残留 入库 Obsidian / Notion 建索引、加标签、全文检索
全程不需要付费工具,不需要GUI操作,一台电脑 + 一个终端搞定。
写在最后
公众号是中文互联网最大的内容金矿,也是围墙最高的花园。
但围墙从来不是为了保护内容,而是为了保护流量。对于真正想学习、想研究、想建立自己知识体系的人来说,把内容从平台搬到自己的知识库,不是搬运,是自救。
毕竟,你永远不知道一个公众号什么时候会停更、迁移、或者被封。
你的知识库,应该由你自己掌控。