Cloudflare Worker + 域名:零成本搭建私人爬虫代理池

Cloudflare Worker 的免费额度是每天 10 万次请求,全球 300+ 边缘节点,出口 IP 分布在几十个国家。 绑上自己的域名,只需 10 分钟就能搭一个私人代理池,域名是唯一的成本。免费额度足够个人使用。 最主要的是:还能用来抓取公众号文章。
Worker 为什么能做代理
Cloudflare Worker 运行在边缘节点上。发一个请求给 Worker,Worker 再去请求目标网站——目标网站看到的 IP,是 Cloudflare 的边缘节点 IP,不是本机 IP。
每次请求走哪个边缘节点,由 Cloudflare 的路由决定,无法精确控制,但这反而带来了自然的 IP 轮换效果。配合多个 Worker 路由或子域名,可以进一步分散请求来源。
准备材料
- Cloudflare 账号(免费)
- 一个域名
创建与配置 Worker
登录 Cloudflare Dashboard → Workers & Pages → 创建应用程序,选择「从 Hello World! 开始」:
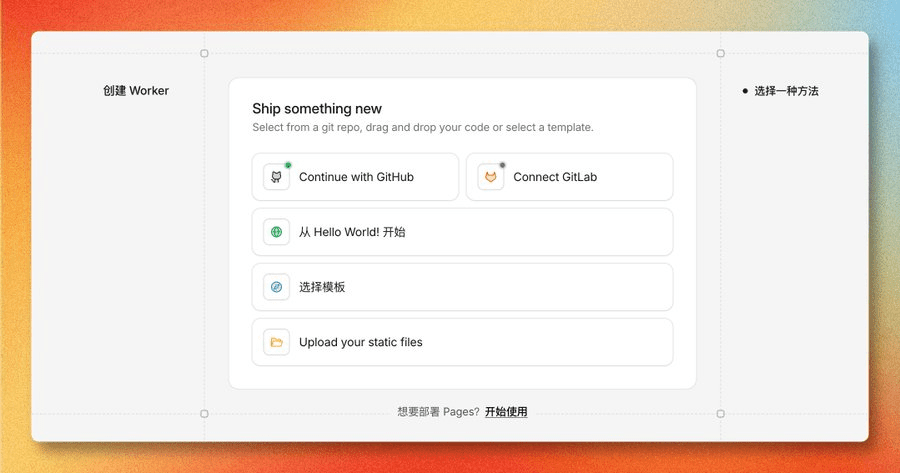
然后点击部署:
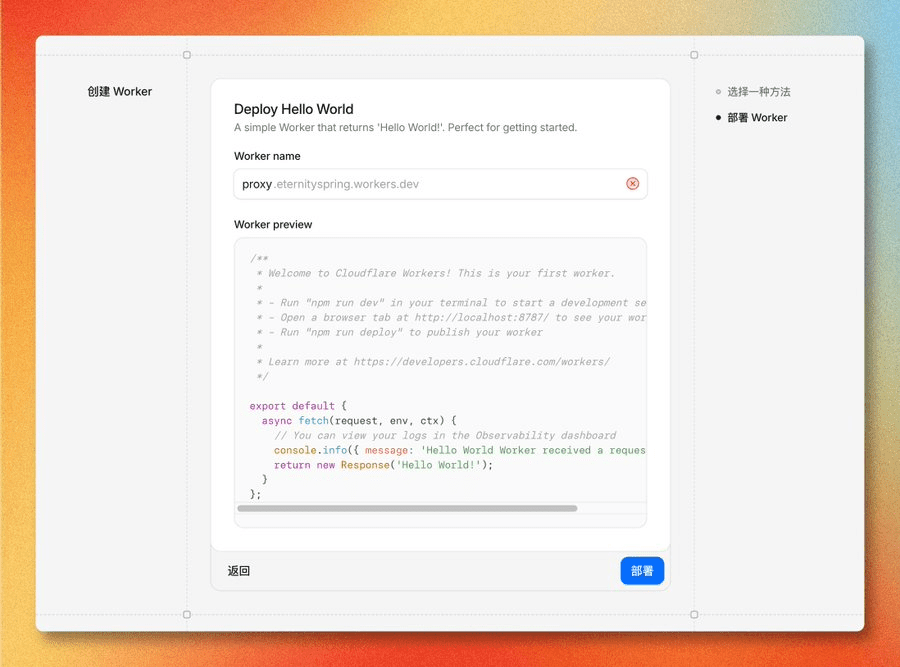
创建 Worker
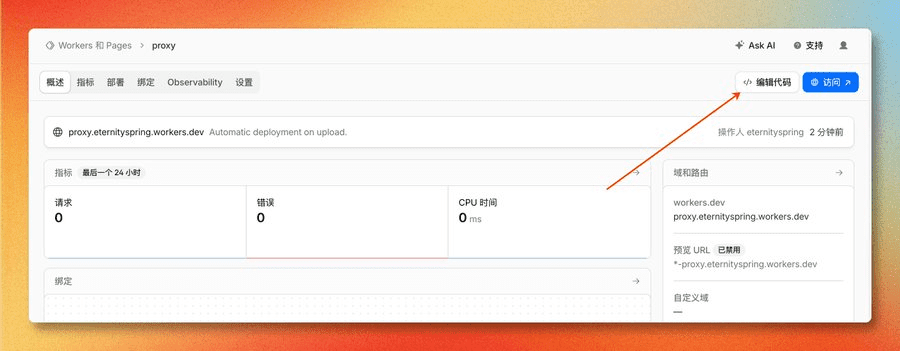
等待部署完成,点击编辑代码
命名并部署
把默认代码替换为:
const UA =
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.0.0 Safari/537.36";
const PRESETS = {
wechat: {
Referer: "https://mp.weixin.qq.com",
},
};
const CORS_HEADERS = {
"Access-Control-Allow-Origin": "*",
"Access-Control-Allow-Methods": "GET, POST, OPTIONS",
"Access-Control-Allow-Headers": "Content-Type",
"Access-Control-Max-Age": "86400",
};
function error(msg, status = 400) {
return new Response(msg, { status, headers: CORS_HEADERS });
}
function checkToken(req, env) {
if (!env.TOKEN) return; // 未配置 token 则跳过校验
const authHeader = req.headers.get("Authorization") || "";
const token = authHeader.startsWith("Bearer ")
? authHeader.slice(7)
: new URL(req.url).searchParams.get("token");
if (token !== env.TOKEN) throw new Error("Unauthorized");
}
async function parseRequest(req) {
const origin = req.headers.get("origin") || "*";
let targetURL = "";
let targetMethod = "GET";
let targetBody = "";
let targetHeaders = {};
let preset = "";
const method = req.method.toLowerCase();
if (method === "get") {
const { searchParams } = new URL(req.url);
targetURL = searchParams.get("url") || "";
if (searchParams.has("method")) targetMethod = searchParams.get("method").toUpperCase();
targetBody = searchParams.get("body") || "";
if (searchParams.has("headers")) {
try {
targetHeaders = JSON.parse(searchParams.get("headers"));
} catch (_) {
throw new Error("headers not valid");
}
}
preset = searchParams.get("platform") || searchParams.get("preset") || "";
} else if (method === "post") {
const payload = await req.json();
if (payload.url) targetURL = payload.url;
if (payload.method) targetMethod = payload.method.toUpperCase();
if (payload.body) targetBody = payload.body;
if (payload.headers) targetHeaders = payload.headers;
preset = payload.platform || payload.preset || "";
} else {
throw new Error("Method not implemented");
}
if (!targetURL) throw new Error("URL not found");
if (!/^https?:\/\//.test(targetURL)) throw new Error("URL not valid");
if (targetMethod === "GET" && targetBody) throw new Error("GET method can't have body");
if (Object.prototype.toString.call(targetHeaders) !== "[object Object]") {
throw new Error("Headers not valid");
}
if (!targetHeaders["User-Agent"]) targetHeaders["User-Agent"] = UA;
if (preset in PRESETS) Object.assign(targetHeaders, PRESETS[preset]);
return { origin, targetURL, targetMethod, targetBody, targetHeaders };
}
export default {
async fetch(request, env) {
if (request.method === "OPTIONS") {
return new Response(null, { status: 204, headers: CORS_HEADERS });
}
try {
checkToken(request, env);
const { origin, targetURL, targetMethod, targetBody, targetHeaders } =
await parseRequest(request);
const response = await fetch(targetURL, {
method: targetMethod,
body: targetBody || undefined,
headers: targetHeaders,
});
return new Response(response.body, {
status: response.status,
headers: {
...CORS_HEADERS,
"Access-Control-Allow-Origin": origin,
"Content-Type": response.headers.get("Content-Type"),
},
});
} catch (err) {
const status = err.message === "Unauthorized" ? 401 : 400;
return error(err.message, status);
}
},
};
点击右侧预览 tab 下的刷新按钮,看到页面出现 URL not found,说明代码可用。接着点击部署。
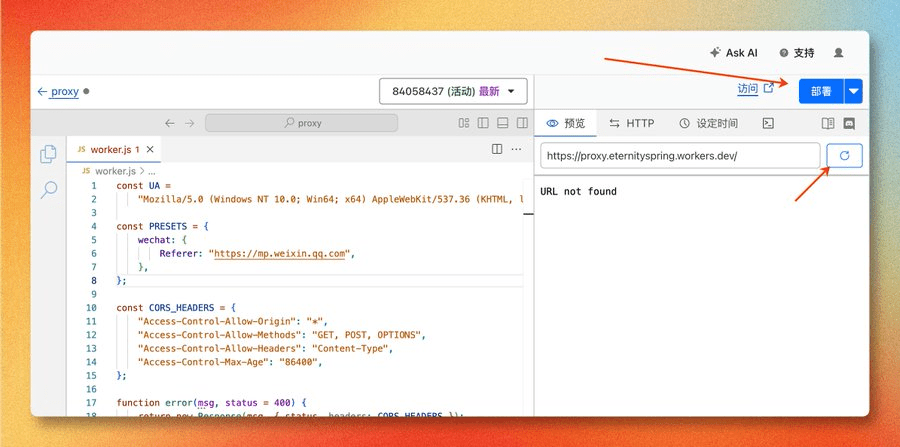
预览显示 URL not found,代码正常
注意:免费的 Cloudflare 有部署次数限制,建议在此调试完成再部署。
绑定自定义域名
Worker 默认会分配一个 *.workers.dev 的子域名,可以直接用,但有两个问题:
- workers.dev 已经被部分目标网站加入黑名单,在国内访问不稳定,且容易被封。
- 不好记,轮换管理麻烦
在 Worker 设置页面,点击域和路由右侧的添加按钮,会出现两个选项:自定义域和路由。选择自定义域,输入要绑定的域名,添加完成后就能在设置中看到:
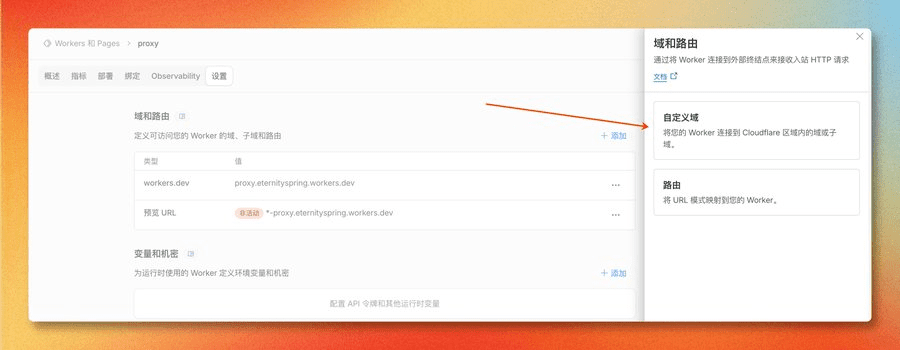
点击添加,选择自定义域
添加完成后就能在设置中看到:
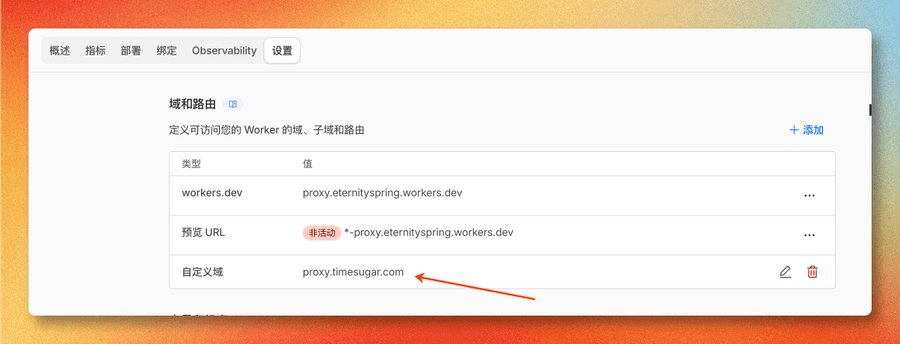
自定义域添加完成
这里简单说一下两个选项的区别:自定义域需要逐个绑定。路由支持批量,比如填 proxy*.yourdomain.com/*,这样 proxy1、proxy2、proxy3 全部命中同一个 Worker。不同子域名对应不同范围的 Cloudflare 边缘节点,出口 IP 更分散,有搭代理池需求的按路由方式配置。
配置token(可选)
在 Cloudflare Dashboard → Worker → 设置 → 变量和机密 → 添加变量,填写变量名 TOKEN,值设为自己的密钥。
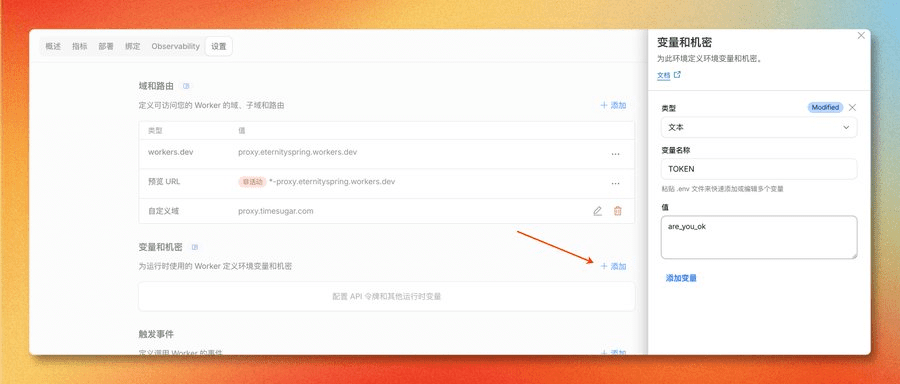
配置 TOKEN 环境变量
未配置 TOKEN 时会直接跳过校验。注意:这意味着任何知道这个 URL 的人都可以借用这个代理。
调用方式
代理上线后,用法是:
https://proxy.yourdomain.com/?url=https://目标网站.com/路径
微信公众号文章调用示例:
https://proxy.yourdomain.com/?url=https://mp.weixin.qq.com/s/xxxxxx&platform=wechat

微信文章调用示例
如果配置了 token,调用时带上:
# query param
?url=https://example.com&token=<密钥>
# 或 Authorization header
Authorization: Bearer <密钥>
题外话:配合 AI 大幅度降本
有了这个代理,你可以做一个「网页解析工作流」:
- 获取内容:通过 Worker 代理爬取网页 HTML。
- 初步清洗:用 Qwen 或 DeepSeek 等廉价模型将 HTML 转为结构化的 Markdown/JSON。
- 深度处理:将清洗后的「精简版」数据交由 Claude 或 GPT 等顶级模型处理。
局限性说明
- IP 并非高匿名:Cloudflare 的 IP 是公开已知的,反爬极强的网站(如使用了 CF 自家防护的)可能会拦截。
- 并发限制:免费版 Worker 虽然每天 10 万次请求,但瞬间并发过高可能会触发频率限制。
适合场景:个人采集、绕过简单的 IP 频率限制、API 转发、小规模结构化数据抓取。
结尾
有了 Cloudflare Worker,自己抓一些简单的数据时候,没必要花钱买别人封装好的代理服务。
Worker 免费,域名最低 ¥4.64/年,10 分钟部署,随用随起。如果哪天请求量真的大到要买代理服务,那时候项目大概也值得花这笔钱了。
核心代码就这几十行,有什么不懂的可以私信评论区讨论。
本文首发于微信公众号:「阿皓AI」,欢迎关注!