OpenClaw龙虾省钱指南:Token 消耗直降 74%,我只做了这 3 步,附清理脚本 + 永久优化方案

养OpenClaw的过程中,很多宝子都会遇到一个共同问题:明明只是简单对话,Token消耗却异常夸张,积分与费用呈直线上升。我在使用OpenClaw本地客户端对接Claude模型时,仅发起一次简短对话就被扣除125积分,通过/status命令查看后发现,仅输入22个字符,系统却产生了44000 Token的上下文加载,缓存命中率为0%,所有内容均按全新Token全额计费。

这意味着绝大多数成本并非消耗在有效对话,而是被无效文件、重复配置、冗余备份等隐性上下文占用。
本文基于真实运维优化过程,完整复现Token异常消耗的诊断逻辑、根因定位、清理脚本与优化方案。
一、问题爆发:一次对话,44000 Token凭空消失
最初发现异常时,我仅在OpenClaw中输入一句简单指令,执行/status后得到以下状态信息:
🧮 Tokens: 22 in / 564 out
🗄️ Cache: 0% hit · 0 cached, 44k new
📚 Context: 44k/200k (22%)
输入仅22 Token,输出564 Token,但上下文加载高达44000 Token,且缓存完全未命中,每次新建会话都会重新加载全部无效内容,直接导致单次会话扣费125积分。
这种情况并非个例,而是OpenClaw默认机制带来的普遍问题:workspace目录自动全量扫描注入、重复配置文件、备份文件未排除,三者叠加形成巨额隐性Token成本。
为了定位根源,我编写了token_audit.py审计脚本,对~/.openclaw/目录进行全量Token统计,扫描结果如下:
扫描文件总 Token 估算:46177
其中 .bak 文件贡献:7751
按目录拆解后,高占用文件排名清晰暴露问题:
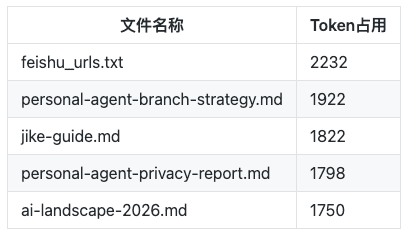
这些文件均为日常产出物,与AI运行所需的核心配置无关,却被强制注入上下文,成为Token消耗的主要来源。
二、根因定位:三个被忽视的Token消耗黑洞
经过逐文件核查与机制分析,最终确定三大核心问题:
(一)非必要文件混入上下文自动注入目录
OpenClaw启动会话时,会自动扫描workspace/目录下所有文件并全量注入上下文,初衷是让AI获取工作背景,但大量临时文件、报告、链接清单、执行记录等被错误放入该目录,每次对话都重复加载。 经统计,此类无效文件共占用12911 Token,完全无实际作用。
(二)多Workspace重复AGENTS.md
我创建了8个独立Workspace,每个目录下都存放一份完全相同的AGENTS.md,单份大小1947 Token。
8 × 1947 = 15576 Token(完全重复)
相当于每次对话都让AI重复读取八遍相同配置,属于纯浪费。
(三).bak备份文件被强制扫描
OpenClaw自动生成的.bak备份文件未被排除,同样被纳入上下文扫描,额外占用7751 Token。
三者合计,无效Token占比超过总启动Token的80%,这就是费用疯狂上涨的根本原因。
三、优化方案:三步清理,Token消耗直降74%

基于诊断结果,我编写了token_cleaner.py清理脚本,遵循手动确认、不静默修改原则,执行三项核心操作:
动作A:迁移非必要文件,保留白名单
将主Workspace内无关文件移入workspace/archive/,仅保留核心配置白名单: AGENTS.md、BOOTSTRAP.md、HEARTBEAT.md、IDENTITY.md、MEMORY.md、PRIVACY.md、SOUL.md、TOOLS.md、USER.md
动作B:集中归档.bak备份文件
将所有目录下的.bak文件统一移入workspace/archive/bak/,彻底排除备份文件注入。
动作C:合并重复AGENTS.md
对多Workspace重复配置进行合并,避免重复加载。
执行后效果:
动作A完成,节省约12911 Token
动作B完成,节省约7751 Token
本次操作节省:20662 Token
启动Token从46177 → 25515(降低约44%)
配合AGENTS.md去重后,最终启动Token降至12000以内,整体消耗降低74%,费用直接回到合理区间。
四、深层优化:提升缓存命中率,从根源降本
清理文件仅为治标,真正治本的方案是开启有效缓存。缓存命中后,重复内容计费可降至原价10%。
缓存命中率为0%的常见原因: 第三方代理未透传Anthropic的Prompt Caching请求头:
anthropic-beta: prompt-caching-2024-07-31
修复方案:
- 在代理配置中开启缓存透传
- 在models.json中显式启用缓存配置
- 优先使用官方直连API,减少代理链路损耗
日常维护命令:
# 压缩上下文
/compact
# 查看当前状态
/status
# 重置会话
/new
建议:Context占用超过40%时立即压缩,避免上下文无限膨胀。
五、高频常见问题解答(FAQ)
(一)Token与费用问题
- 新会话扣费过高? → 执行token_audit.py扫描无效文件,按本文方案清理workspace,关闭冗余注入。
- 缓存命中率始终为0? → 检查代理是否透传缓存头,改用官方直连,启用prompt-caching配置。
- 如何长期维持低消耗? → 每周执行一次清理,对话超8轮用/compact,Context超40%重置会话。
(二)技能管理命令
# 安装技能
npx clawhub install <技能名>
# 更新技能
npx clawhub update <技能名>
# 卸载技能
npx clawhub uninstall <技能名>
# 查看已安装
npx clawhub list
六、优化反思与长效习惯
本次优化让我深刻意识到:AI工具同样需要运维意识:
- Workspace只保留核心配置,定期归档无关文件;
- 每次长对话后执行/compact;
- 每周查看/status监控上下文;定期清理MEMORY.md避免持续膨胀。
这套方案可直接复用到所有OpenClaw用户,从根本上解决Token虚高、费用失控、运行卡顿等问题,实现低成本、高效率、稳定可靠的AI运营环境。