Token降本三大技巧,告别龙虾天价消耗
最近大家养龙虾养得飞起,但抱怨最多的一件事是:
"Token太贵了,说个’你好’,5块钱没了。"
我自己最高一天烧200多美金。后来摸清楚了,改了三个地方,现在控制在10美金左右。今天把3条秘籍分享出来。
先搞懂:为什么说个"你好"那么贵?
很多人以为,AI按条收费,聊了10条就是10条的钱。
不是这样的。
龙虾每次跟你说话,都要先把记忆装进来——你是谁、有什么规则、你们之前聊了什么,全装进来再开口。
记忆存在 memory.md 里,会越来越大。等积累了几十万字,你一说"你好",它先把几十万字想一遍,再回你。
每句话都想一遍,Token不就飞起来了?
第一招:用好斜杠命令
龙虾有几个特殊命令,直接跟程序交互,不经过大模型,不消耗Token,必须记住:
/new 重开对话,清掉之前的上下文,轻装上阵 /restart 整个龙虾重启,龙虾卡住或不理你时用 /stop 立刻停下手头任务,避免方向跑偏继续烧token /compress 压缩记忆,大事记住小事忘掉,记忆体积大幅缩小
第二招:能用程序搞定就不要用大模型
这一招是被"教训"出来的。
有一天我没怎么聊天,账单出来100多美金。查了发现:我设了每5分钟检查一次邮件——大模型亲自上,每次去读邮件接口判断有没有新邮件,全天不停烧。
解法很简单:让脚本去检查邮件,有新邮件再叫大模型出来。脚本只耗CPU,不耗Token。
这个道理想清楚之后,我在三万家立了一条规则:能用脚本的,不让大模型做。查天气、拉数据、定时检查……全交脚本,大模型只做判断和表达。
AI是你的大脑,不是你的手。让它思考,不要让它搬砖。
那如果你要看份新闻简报,或者做一个网页模板,那怎么办呢?可以试试像我们三万一样形成多agent团队。
第三招:不同任务,用不同模型
这是最能立竿见影省钱的一招。
顶级模型好用,但贵。你的很多任务根本不需要那么贵的模型。
复杂的事用贵的,简单的事用便宜的。
国产大模型今天已经便宜又好用。整理简报、搞调研、生成文档——完全够用,成本是顶级模型的几十分之一。
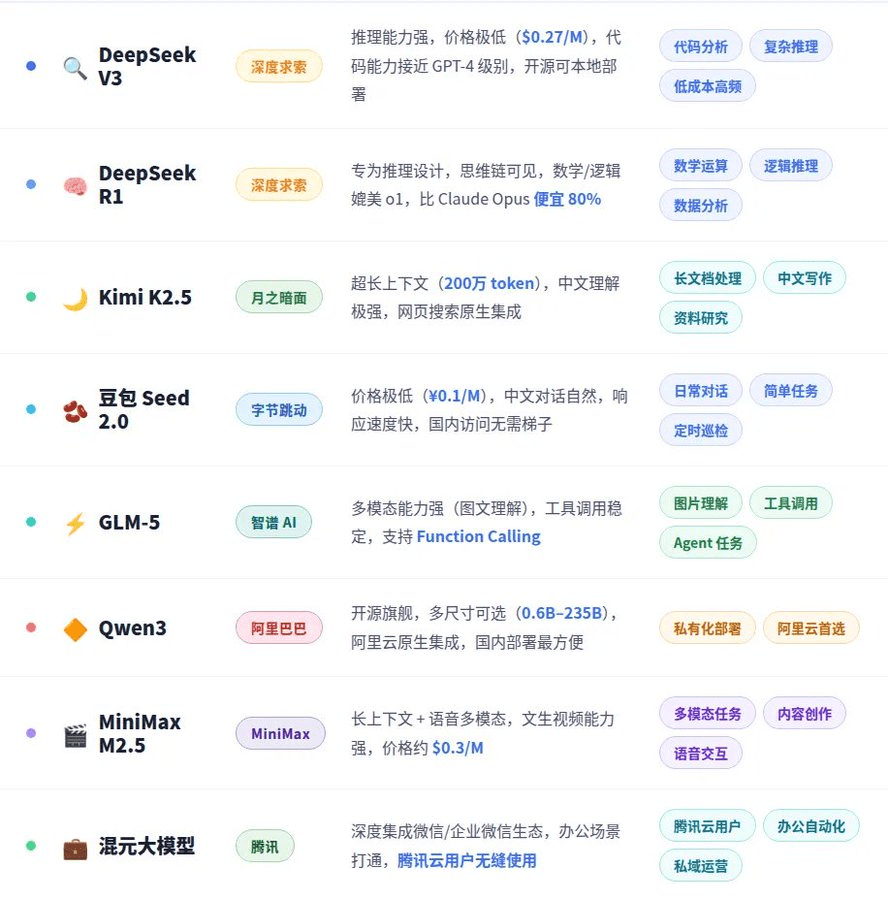
我跟三万商量,每天刷资讯这件事专门配了"爬虾",用最便宜的国产模型每30分钟跑一遍。这一项从几十美金,直接降到一天几美金。

分配逻辑很简单:写代码、深度创作,用贵的;整理信息、重复任务,用便宜的。龙虾支持给不同任务单独指定模型,配好之后自动分流,不用每次手动切。
写在最后
斜杠命令、脚本优先、模型分级。三招合用,降本90%不难。
很多人抱怨AI太贵,用不起——但真相是,同样的工具,用法不同,成本能差出十倍。
贵不是因为AI本身,贵是因为你让它做了太多它不该做的事,记住了太多它不该记的东西。
把对的事交给对的工具,AI才能真正值回它的价钱。
降低AI对话成本的三大核心策略
问题核心:为何一句"你好"如此昂贵?
AI对话成本并非按条计费,而是与上下文记忆规模直接相关。每次交互时,模型需加载全部历史对话、规则及记忆(存储于memory.md),导致重复内容持续膨胀,最终触发高额Token消耗。
第一招:善用斜杠命令(零Token指令)
通过直接与底层程序交互,规避模型计算:
/new:清空当前对话历史,轻量化交互/restart:强制重启AI进程,解决卡顿或异常/stop:终止当前任务,防止跑题烧钱/compress:智能压缩记忆文件,保留关键信息并删除冗余
第二招:脚本替代模型(区分"脑力"与"体力")
AI应专注于复杂决策(大脑功能),而非机械执行(体力劳动):
-
脚本场景:定时任务(如查邮件)、数据拉取、格式化操作
-
模型场景:创意生成、逻辑推理、多轮交互
-
多Agent协作示例:
- 脚本负责爬取新闻数据 → 模型生成简报
- 脚本监控文件变化 → 模型触发响应
第三招:模型分级(按需匹配计算资源)
- 高成本模型(如顶级闭源模型):保留用于核心场景(代码开发、深度创作)
- 低成本模型(如国产开源模型):处理标准化任务(信息整理、重复操作)
- 实证案例:资讯整理任务切换至低价模型后,日成本从$30+降至$5内
总结:成本优化公式 = 斜杠命令 + 脚本分流 + 模型分级
三者协同可使成本降低90%以上。关键逻辑在于:
- 最小化记忆负载(定期压缩/重置)
- 任务分流(脚本处理重复性,模型专注创造性)
- 资源匹配(避免用"核动力引擎"驱动自行车)
AI的价值在于智能决策,而非体力劳动。善用工具层级,方能实现效费比最大化。
文章作者:大神K
版权说明:本文为原创内容,转载请注明出处。