Hermes + Qwen3.6:本地最强 Agent 组合!零成本、无限 Token,太香了!
Hermes + Qwen3.6:本地最强 Agent 组合!零成本、无限 Token,太香了!
如果现在让我推荐一套最适合普通用户跑本地模型 + Agent 的方案,我会毫不犹豫地推荐:Hermes + Qwen3.6 最新开源模型。这套组合最大的优势就是:免费、好用、灵活,而且非常适合日常使用。
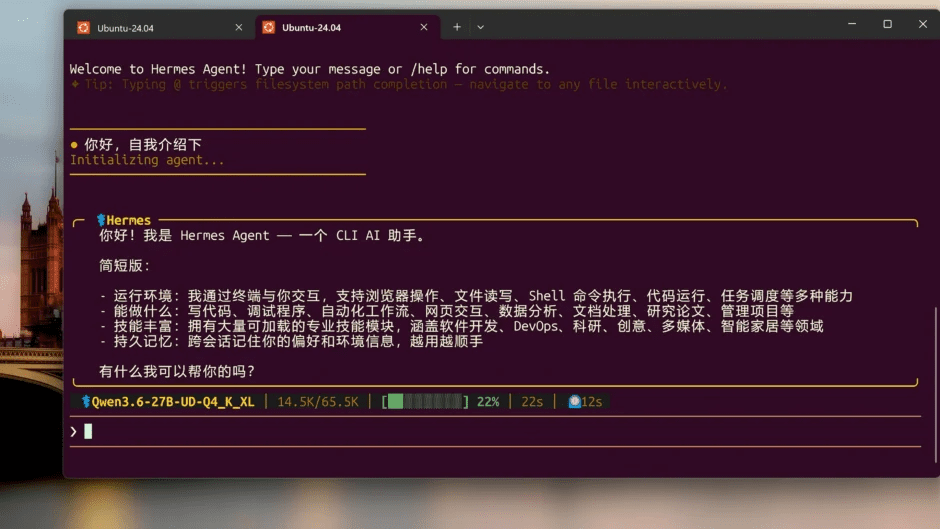
无论你是想让 AI 帮你处理自动化任务,还是辅助代码编写、中文理解、逻辑推理,Qwen3.6 都已经可以满足大多数人的日常需求。相比很多需要订阅、需要充值 Token 的在线 AI 服务,本地部署最大的好处就是——真正做到 Token 自由。
你不用担心每次对话都在消耗额度,也不用每个月支付固定会员费。模型运行在自己的电脑上,数据不上传到第三方平台,隐私也完全掌握在自己手里。而 Hermes Agent 的加入,则让这套方案变得更加实用。
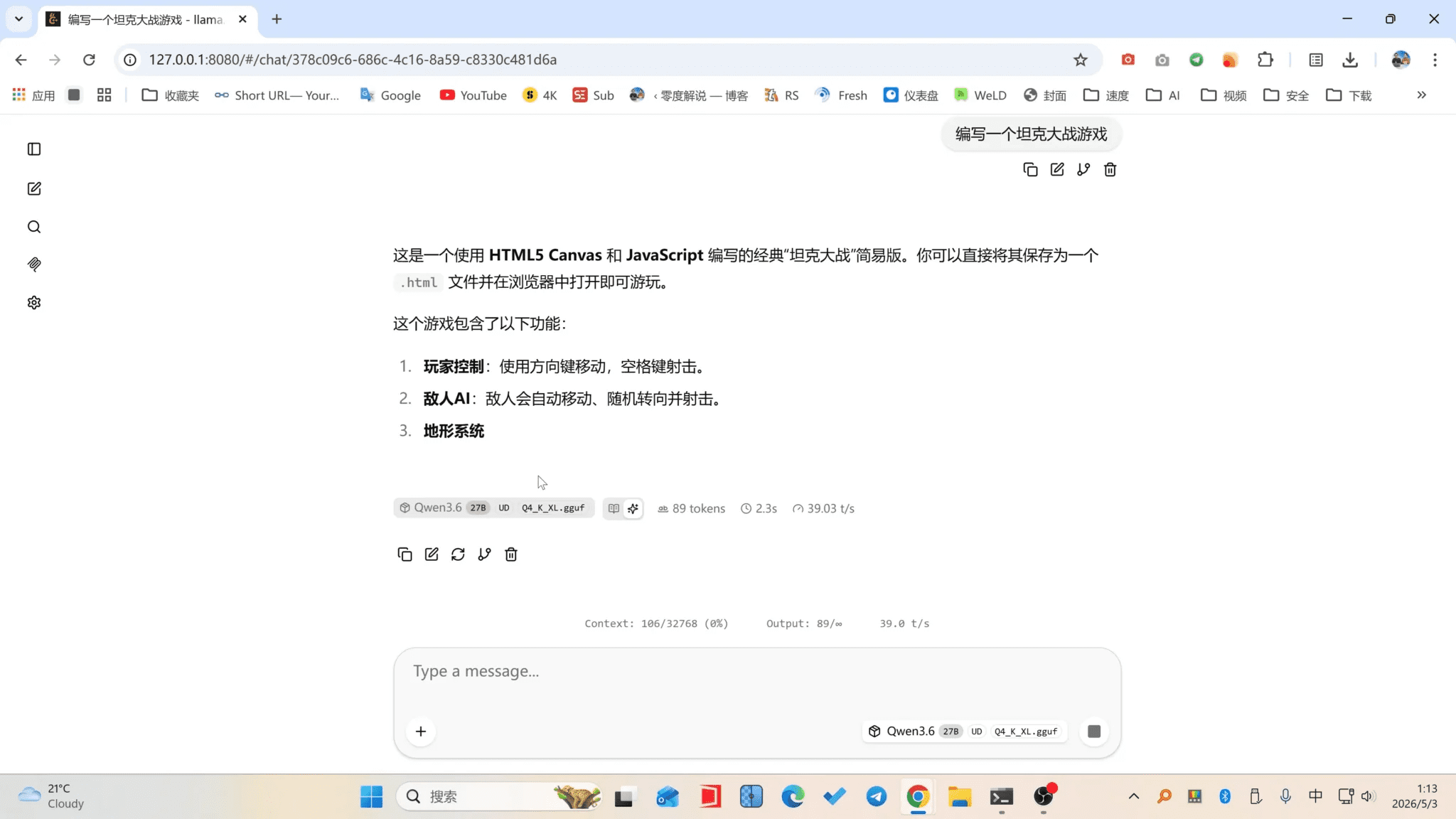
部署完成后,你可以把它变成一个真正属于自己的 AI 助手:
支持手机随时对话,支持开机自动启动,也可以长时间保持在线。无论是写代码、查资料、整理内容,还是执行一些自动化操作,它都可以成为你电脑上的 24 小时 AI 助理。

简单来说,Hermes 负责 Agent 能力,Qwen3.6 负责大模型能力。两者结合之后,就可以在本地打造一套免费、私有、可长期使用的 AI 工作流。
对于想体验本地 AI、又不想被 Token 限制的朋友来说,这套方案非常值得尝试。
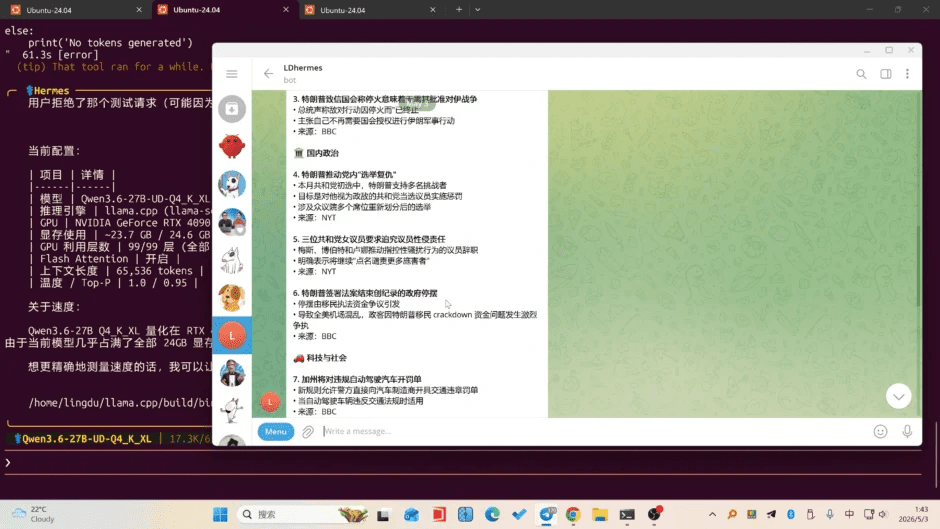
接下来,我会从零开始,带大家一步一步把 Hermes + Qwen3.6 部署到自己的电脑上,让你的本地 AI 助手真正跑起来。
部署教程:
第一步:确认环境并安装WSL
# PowerShell 管理员运行
wsl --install # 装 Ubuntu 24.04
wsl --set-default-version 2
重启后再执行安装Ubuntu 24.04系统
装完会自动重启,重启后会弹出 Ubuntu 窗口让你设置用户名和密码(随便设,记住就行)。
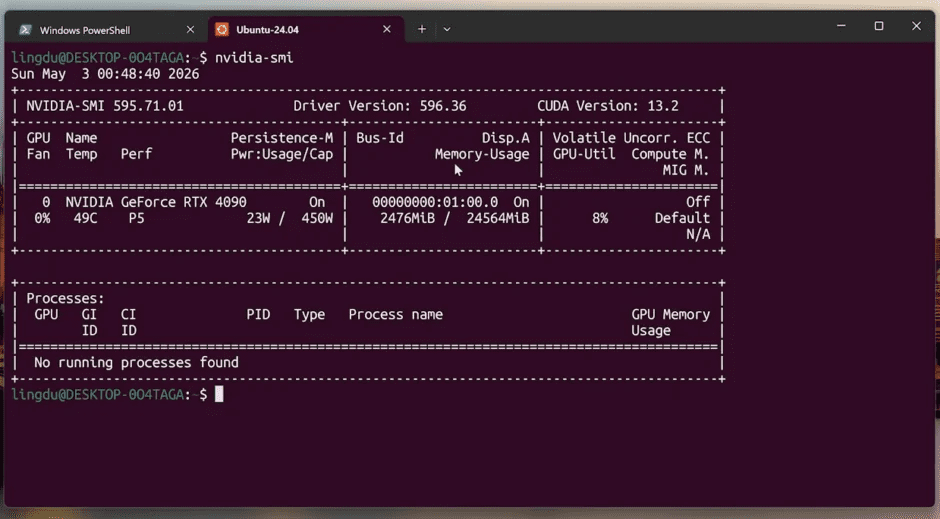
Ubuntu 24.04 装好并登录成功,现在先验证 GPU 是否直通正常:
nvidia-smi
第二步:装 Python 和 pip
sudo apt update && sudo apt install -y python3-pip python3-venv
如果你出现下方这个错误的话,那么主要是因为显卡驱动太旧了,现在我们去更新下驱动!
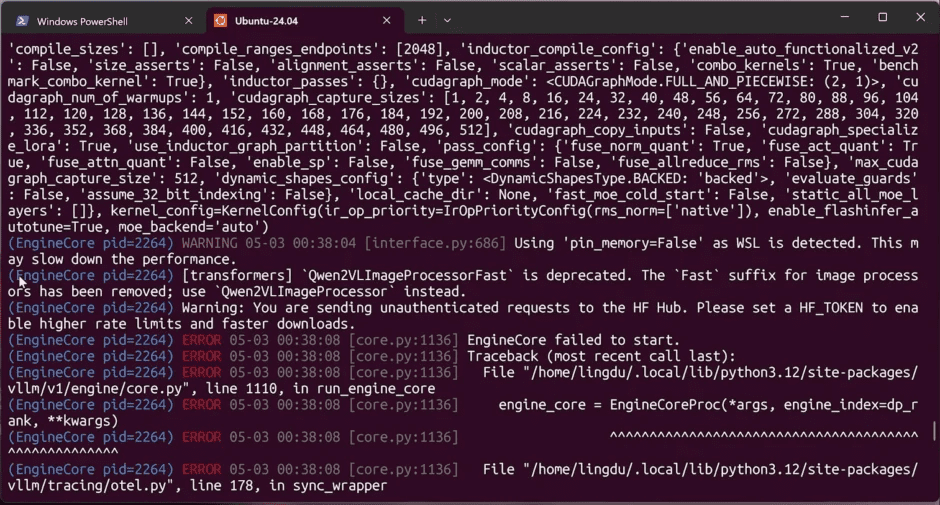
升级 Windows NVIDIA 驱动 【点击前往】去 Windows 下载最新驱动,WSL2 会自动继承;
更新驱动以后,本来我是想通过vllm或者DFlash进行加速运行,但是考虑到很多人的显存没有那么大,可能会爆显存所以我们改用 llama.cpp 方案,更稳定。
第三步:安装 llama.cpp
sudo apt install -y cmake build-essential git
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
cmake -B build -DGGML_CUDA=ON -DCMAKE_CUDA_ARCHITECTURES=89
cmake --build build -j$(nproc)
好,如果出现这个错误的话,这主要是因为 CUDA Toolkit 没装导致的。WSL2 里需要单独装,运行:
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2404/x86_64/cuda-keyring_1.1-1_all.deb
sudo dpkg -i cuda-keyring_1.1-1_all.deb
sudo apt update
sudo apt install -y cuda-toolkit-12-8
这个下载比较大(约2GB),耐心等…. 下载好以后现在设置路径然后重新编译:
export PATH=/usr/local/cuda-12.8/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-12.8/lib64:$LD_LIBRARY_PATH
echo 'export PATH=/usr/local/cuda-12.8/bin:$PATH' >> ~/.bashrc
echo 'export LD_LIBRARY_PATH=/usr/local/cuda-12.8/lib64:$LD_LIBRARY_PATH' >> ~/.bashrc
cd ~/llama.cpp
rm -rf build
cmake -B build -DGGML_CUDA=ON -DCMAKE_CUDA_ARCHITECTURES=89
cmake --build build -j$(nproc)
第四步:下载开源的本地模型
编译大概需要5-10分钟,编译成功!现在下载模型并启动,运行:
hf download unsloth/Qwen3.6-27B-GGUF \
Qwen3.6-27B-UD-Q4_K_XL.gguf \
--local-dir ~/models/
这个文件约 17GB,下载完贴最后几行,我们再启动服务。如果下载很慢或卡住,那么你可以切换到 ModelScope 国内镜像。
这里需要注意,因为我的显存是24G的,所有我选择 Qwen3.6-27B,如果你的显存没这么大,那么可以选择尺寸小一点的模型,比如Qwen3.5
下载好模型以后,现在启动模型服务:(注意把下方命令中的模型名称替换成你自己的):
~/llama.cpp/build/bin/llama-server \
--model ~/models/Qwen3.6-27B-UD-Q4_K_XL.gguf \
--n-gpu-layers 99 \
--ctx-size 32768 \
--flash-attn on \
--temp 1.0 \
--top-p 0.95 \
--top-k 20 \
--presence-penalty 1.5 \
--port 8080
🎉 成功启动!
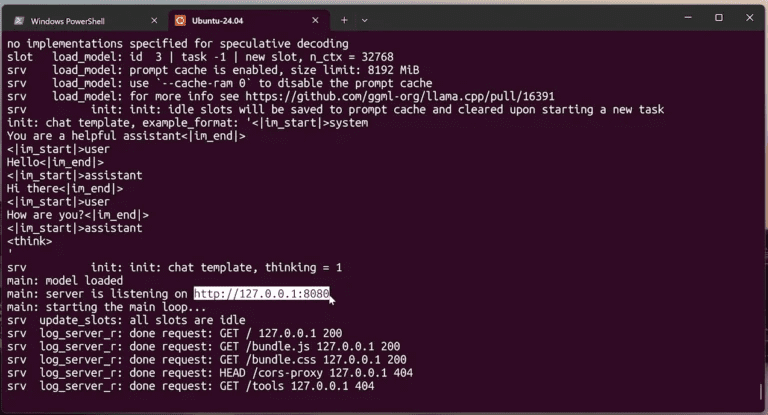
现在打开 Windows 浏览器访问:http://localhost:8080,就能看到内置聊天界面,直接开始和 Qwen3.6-27B 对话了。
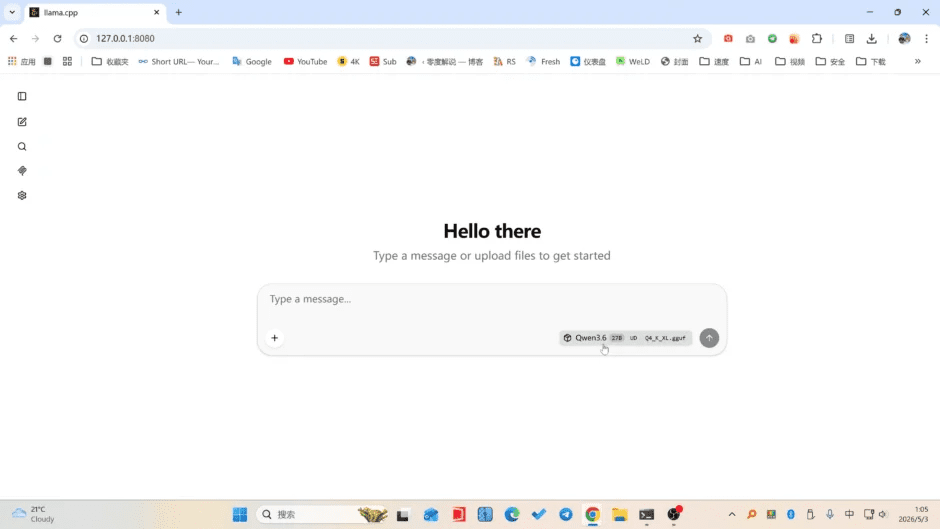
亲测效果极快

默认它是开启深度思考模式的,如果需要关闭 Thinking 模式要在启动命令里加参数,先 Ctrl+C 停掉服务,然后:
~/llama.cpp/build/bin/llama-server \
--model ~/models/Qwen3.6-27B-UD-Q4_K_XL.gguf \
--n-gpu-layers 99 \
--ctx-size 32768 \
--flash-attn on \
--temp 1.0 \
--top-p 0.95 \
--top-k 20 \
--presence-penalty 1.5 \
--chat-template-kwargs '{"enable_thinking":false}' \
--port 8080
关掉 Thinking(非思考模式)
速度快 20-30%
适合:简单问答、写作、代码补全、解释代码
不适合:复杂算法设计、debug 难题、架构分析
开启 Thinking(思考模式)
速度慢,但推理质量明显更好
适合:复杂编程问题、多步骤逻辑、需要深思熟虑的任务
第五步:安装对接 Hermes Agent
第一步:先保持 llama-server 运行(新开一个 WSL2 终端窗口,让模型服务继续跑在 8080)
第二步:在当前终端安装 Hermes Agent
curl -fsSL https://raw.githubusercontent.com/NousResearch/hermes-agent/main/scripts/install.sh | bash
安装程序会自动处理所有依赖(Python、Node.js、ripgrep、ffmpeg),你只需要有 git 就行。
选最后的 Custom endpoint (enter URL manually),然后填:
URL: http://localhost:8080/v1
API Key: 随便填比如 12345678
Model: 会自动识别
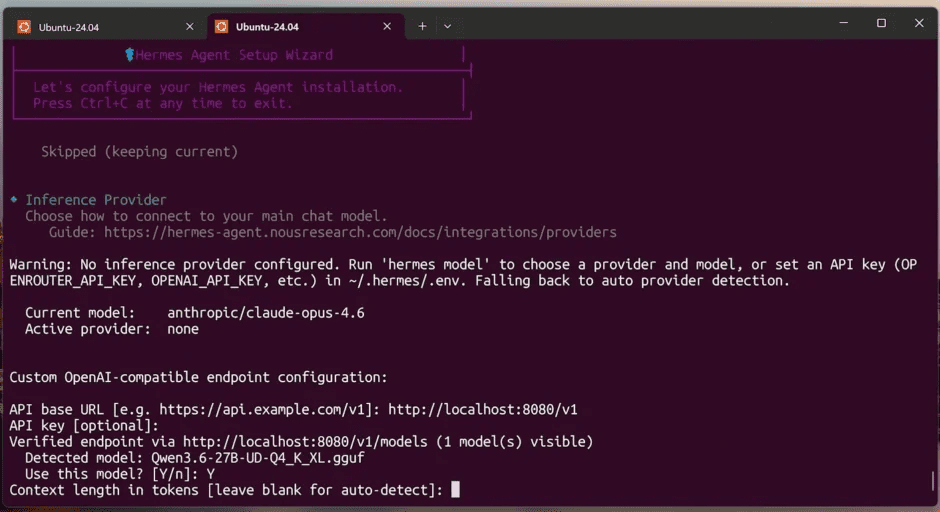
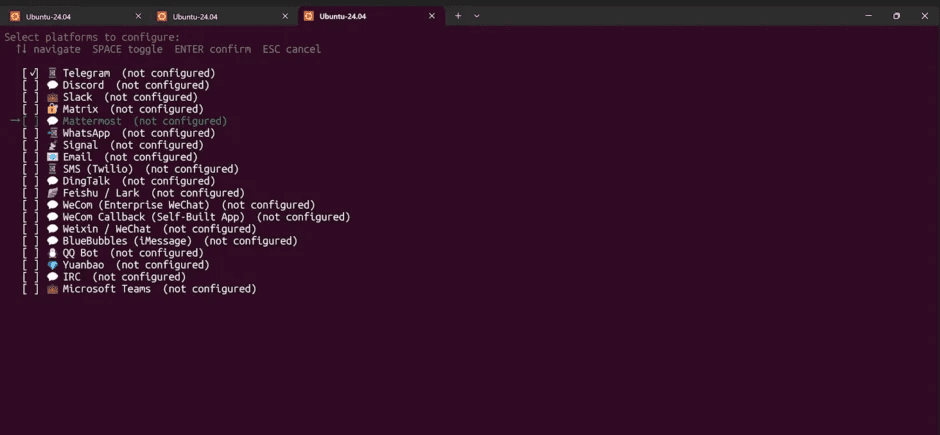
接下来就按照提示,进行配置即可,比如我们可以对接第三方聊天工具:Telegram,当然你可以选择微信、QQ、Discord等
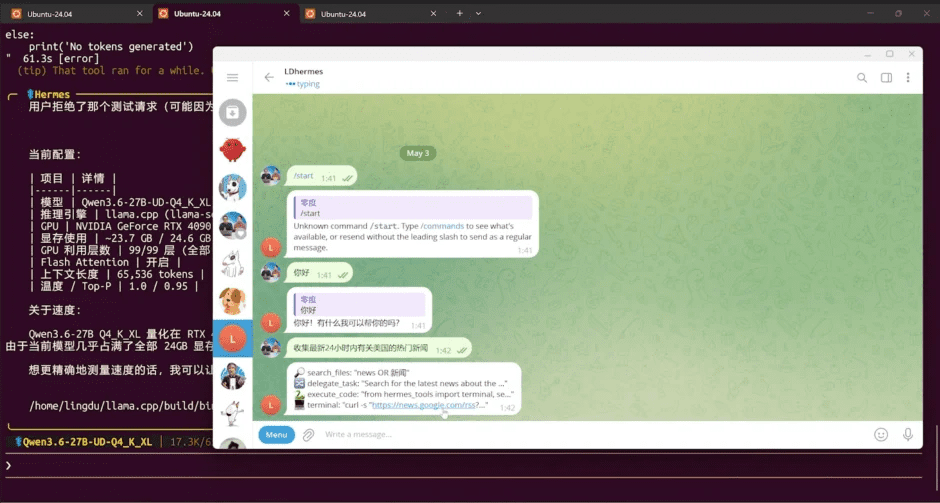
对接以后就可以在任何地方,通过TG来调用并控制电脑上的 Hermes Agent,执行自动化任务, 编写代码,撰写文章等,它就是你24小时帮你免费干活的 AI 助手和代理!
最后我们写个启动脚本,每次开机自动启动 llama-server,不用手动跑命令。创建一个启动脚本,每次打开 WSL2 自动启动 llama-server。
先创建脚本文件:
cat > ~/start-llm.sh << 'EOF'
#!/bin/bash
echo "Starting Qwen3.6-27B llama-server..."
~/llama.cpp/build/bin/llama-server \
--model ~/models/Qwen3.6-27B-UD-Q4_K_XL.gguf \
--n-gpu-layers 99 \
--ctx-size 65536 \
--flash-attn on \
--temp 1.0 \
--top-p 0.95 \
--top-k 20 \
--presence-penalty 1.5 \
--port 8080 \
--host 0.0.0.0 &
echo "llama-server started, PID: $!"
echo "API: http://localhost:8080/v1"
echo "Chat UI: http://localhost:8080"
EOF
chmod +x ~/start-llm.sh
然后设置 WSL2 启动时自动运行:
echo '# Auto-start llama-server' >> ~/.bashrc
echo 'if ! pgrep -f "llama-server" > /dev/null 2>&1; then' >> ~/.bashrc
echo ' ~/start-llm.sh' >> ~/.bashrc
echo 'fi' >> ~/.bashrc
这样每次打开 WSL2 终端,如果 llama-server 没在跑就自动启动,已经在跑就跳过不重复启动。